背景
AWS re:invent にて、Amazon Managed Service for Grafana と、Amazon Managed Service for Prometheus が発表されたことで、
予め冗長構成が取れた監視基盤が簡単に利用できるようになったと(思っているので)、
今後、どちらも触る機会が出てくるかもしれないことから個人的な勉強をまとめています。
監視基盤としては、これまで Zabbix を主にオンプレミス環境で取り扱っていたので、
基盤自体が落ちていないかといった別の機器から監視というループにハマることが多く、
言い出したらきりがなく嫌だなと思っていました。
AWSではCloudWatch logsあるじゃないと思われる一方、
AWSがここに来てこのサービスを発表したということは、
ユーザからの期待・要望があったから発表したと思い(それがAWSですし)
実際に触ってみることで見えてくることがあると思ったので、
今回は、自宅内に機器があるので、それらを監視することを実施してみようと思います。
OSネイティブに細かく構築しても原理を理解するのも選択肢で考えたのですが、
マネージドサービスを使う=設定のみフォーカスに当てたい、と思いDockerで楽をしました。
また、お試しの通知先もSlackとベタな方法にしています。
Zabbixのパスワードが分からなくなったしMySQLのパスワードリセット作業が面倒くさいから丁度いい機会だと思ったとは言いづらいGoogle Chatも一瞬通知先に考えたものの先日の障害で依存はよくないと思った
作成物
Grafana - dashboard
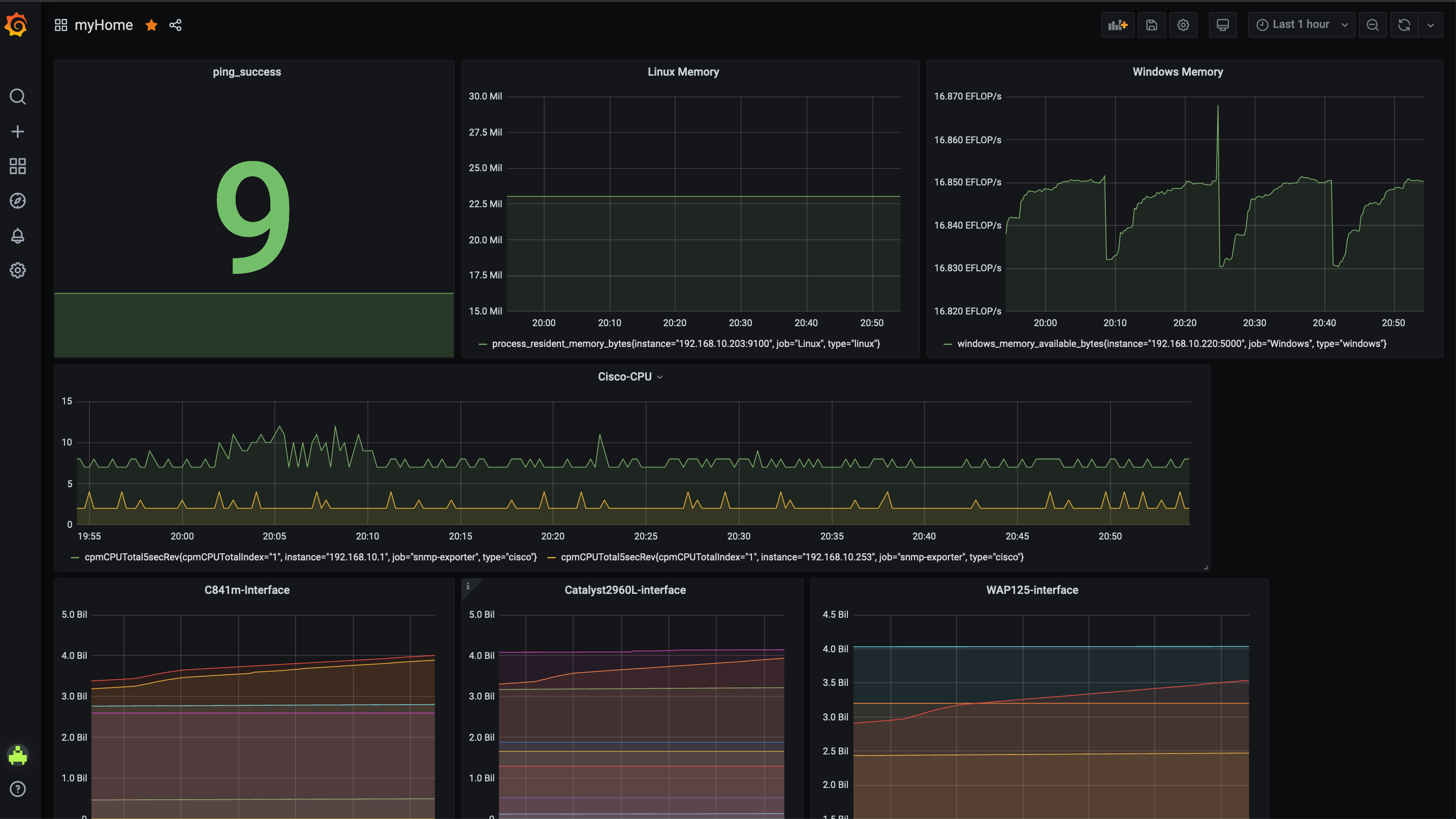
Prometheus - target
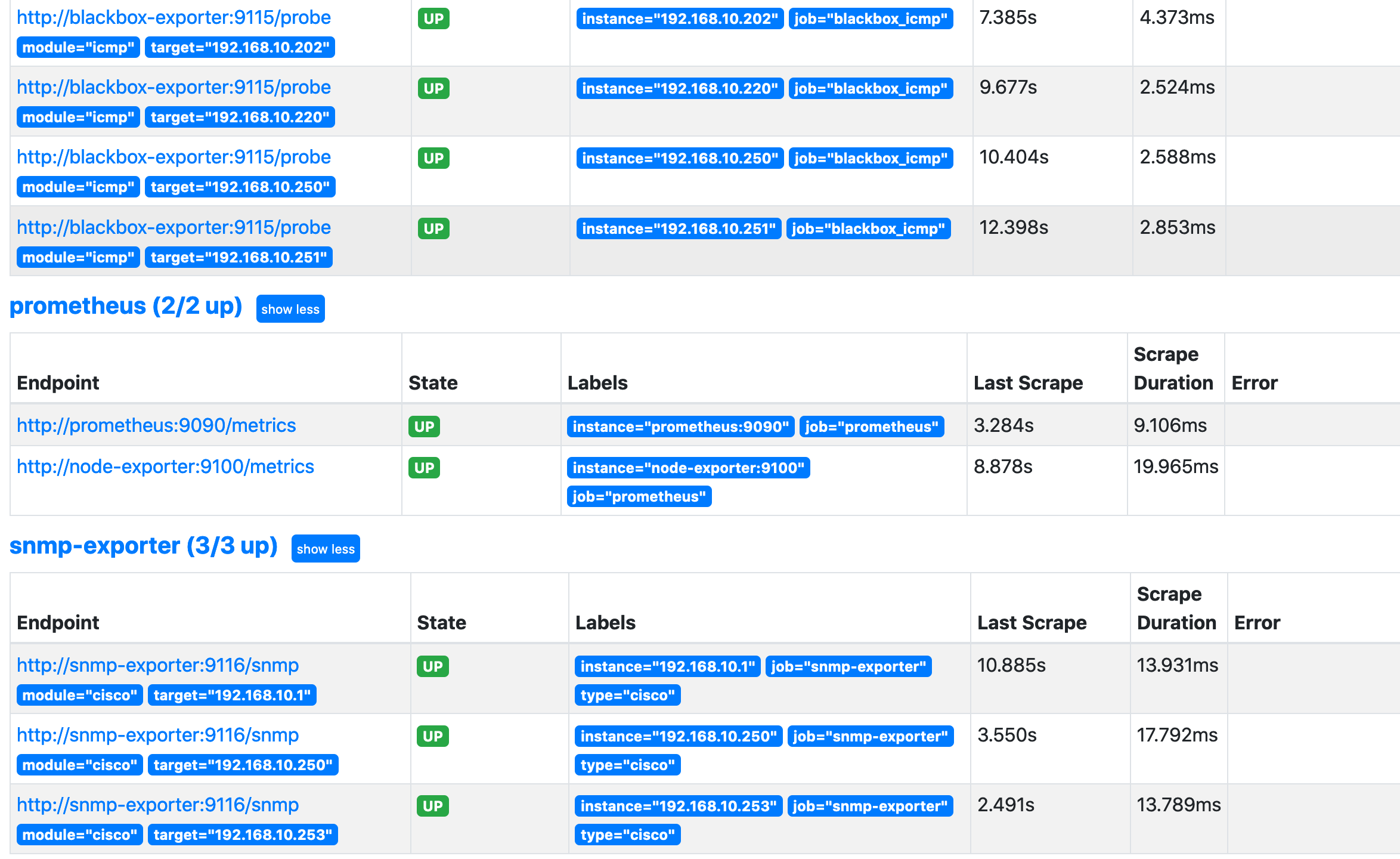
基盤
Grafana(可視化)
- Ubuntu 18.04.5 LTS
- git version 2.17.1
- Docker version 20.10.1, build 831ebea
Prometheus(監視基盤) + AlertManager(通知) + SNMP-Exporter(SNMP収集) + Blackbox-Exporter(外部監視)
- Ubuntu 18.04.5 LTS
- git version 2.17.1
- Docker version 20.10.1, build 831ebea
- docker-compose version 1.27.4, build 40524192
監視対象
Firewall
Router
Switch
Wireless AP
Linux
- CentOS7 - syslog server
- node_exporter-1.0.1.linux-amd64.tar.gz
- install & Settings
sudo groupadd -g 10001 prometheus
sudo useradd -u 10001 -g 10001 -s /sbin/nologin -M prometheus
wget <https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz>
sudo tar zxvf ./node_exporter-1.0.1.linux-amd64.tar.gz -C /opt/
cd /opt/
sudo mv node_exporter-1.0.1.linux-amd64 node_exporter
sudo chown -R prometheus:prometheus node_exporter/
cd /etc/systemd/system/
sudo vi prometheus-node-exporter.service
****************************************
[Unit]
Description=node_exporter for Prometheus
[Service]
Restart=always
User=prometheus
ExecStart=/opt/node_exporter/node_exporter
ExecReload=/bin/kill -HUP $MAINPID
TimeoutStopSec=20s
SendSIGKILL=no
[Install]
WantedBy=multi-user.target
****************************************
sudo systemctl daemon-reload
sudo systemctl status prometheus-node-exporter.service
sudo systemctl start prometheus-node-exporter.service
sudo systemctl status prometheus-node-exporter.service
sudo systemctl enable prometheus-node-exporter.service
Windows
- Windows Server 2019 - AD/DNS/DHCP
- windows_exporter-0.15.0-amd64.msi
- install & Settings
msiexec /i windows_exporter-0.15.0-amd64.msi ENABLED_COLLECTORS="ad,cpu,dhcp,dns,iis,net,os,logical_disk,memory" LISTEN_PORT=5000 TEXTFILE_DIR="C:\\custom_metrics\\"
Grafana
Docker
sudo docker run -d --name=grafana -p 3000:3000 grafana/grafana:7.3.6-ubuntu
Prometheus
Docker
フォルダ構成
myhome-prometheus
└── src
├── alertmanager
│ └── config.yml
├── blackbox_exporter
│ └── config.yml
├── docker
│ └── docker-compose.yml
├── prometheus
│ ├── prometheus.yml
│ └── rules.yml
└── snmp_exporter
└── snmp.yml
Create Cotainers
cd myhome-prometheus/src/docker
pwd
ls -l ./docker-compose.yml
ls -l ../prometheus/prometheus.yml
ls -l ../prometheus/rules.yml
ls -l ../snmp_exporter/snmp.yml
ls -l ../alertmanager/config.yml
ls -l ../blackbox_exporter/config.yml
sudo docker-compose up -d
sudo docker-compose ps
******************************
Name Command State Ports
-----------------------------------------------------------------------------------
alertmanager /bin/alertmanager --config ... Up 0.0.0.0:9093->9093/tcp
blackbox-exporter /bin/blackbox_exporter --c ... Up 0.0.0.0:9115->9115/tcp
node-exporter /bin/node_exporter Up 0.0.0.0:9100->9100/tcp
prometheus /bin/prometheus --config.f ... Up 0.0.0.0:9090->9090/tcp
snmp-exporter /bin/snmp_exporter --confi ... Up 0.0.0.0:9116->9116/tcp
*******************************
docker-compose.yml
version: '3'
services:
prometheus:
image: prom/prometheus:v2.23.0
container_name: prometheus
volumes:
- ../prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- ../prometheus/rules.yml:/etc/prometheus/rules.yml
ports:
- 9090:9090
restart: always
exporter:
image: prom/node-exporter:v1.0.1
container_name: node-exporter
ports:
- 9100:9100
restart: always
snmp-exporter:
image: prom/snmp-exporter:v0.19.0
container_name: snmp-exporter
volumes:
- ../snmp_exporter/snmp.yml:/etc/snmp_exporter/snmp.yml
ports:
- 9116:9116
restart: always
alertmanager:
image: prom/alertmanager:v0.21.0
container_name: alertmanager
volumes:
- ../alertmanager/config.yml:/etc/alertmanager/config.yml
command: "--config.file=/etc/alertmanager/config.yml"
ports:
- 9093:9093
restart: always
blackbox-exporter:
image: prom/blackbox-exporter:v0.18.0
container_name: blackbox-exporter
ports:
- 9115:9115
volumes:
- ../blackbox_exporter/config.yml:/etc/blackbox_exporter/config.yml
prometheus
- prometheus.yml
## my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
## Alertmanager configuration
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- alertmanager:9093
## Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- rules.yml
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets:
- prometheus:9090
- node-exporter:9100
- job_name: 'Linux'
static_configs:
- labels:
type: linux
targets:
- 192.168.10.203:9100
- job_name: 'Windows'
static_configs:
- labels:
type: windows
targets:
- 192.168.10.220:5000
- job_name: 'snmp-exporter'
static_configs:
- labels:
type: cisco
targets:
- 192.168.10.1
- 192.168.10.250
- 192.168.10.253
metrics_path: /snmp
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- source_labels: [type]
target_label: __param_module
- target_label: __address__
replacement: snmp-exporter:9116
- job_name: 'blackbox_icmp'
metrics_path: /probe
params:
module: [icmp]
static_configs:
- targets:
- 192.168.10.1
- 192.168.10.150
- 192.168.10.200
- 192.168.10.202
- 192.168.10.203
- 192.168.10.220
- 192.168.10.250
- 192.168.10.251
- 192.168.10.253
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox-exporter:9115
- rules.yaml
とりあえず死活監視をしようと思って、最低限の監視です。
groups:
- name: checkInstance
rules:
- alert: NodeInstanceDown
expr: up{job='Linux'} == 0
for: 30s
labels:
severity: critical
- alert: pingInstance
expr: up{job='blackbox_icmp'} == 0
for: 2m
labels:
severity: critical
alertmanager
- config.yml
global:
slack_api_url: '<https://hooks.slack.com/services/**********************t>'
route:
receiver: 'slack'
receivers:
- name: 'slack'
slack_configs:
- channel: '#myhome'
snmp-exporter
とりあえずCisco機器のMIBを設定して最低限の確認としています。
なお、SNMP_Exporterのリポジトリでも手動でメンテナンスするのではなく、
同梱されているgeneratorで生成することを謳われています
This file is not intended to be written by hand, rather use the generator to generate it for you.
- snmp.yml
cisco:
walk:
- 1.3.6.1.2.1.2.2.1.16
- 1.3.6.1.2.1.2.2.1.20
- 1.3.6.1.2.1.31.1.1.1.1
- 1.3.6.1.4.1.9.9.109.1.1.1.1.6
metrics:
- name: ifOutOctets
oid: 1.3.6.1.2.1.2.2.1.16
type: counter
indexes:
- labelname: ifName
type: gauge
lookups:
- labels:
- ifName
labelname: ifName
oid: 1.3.6.1.2.1.31.1.1.1.1
type: DisplayString
- name: ifOutErrors
oid: 1.3.6.1.2.1.2.2.1.20
type: counter
indexes:
- labelname: ifName
type: gauge
lookups:
- labels:
- ifName
labelname: ifName
oid: 1.3.6.1.2.1.31.1.1.1.1
type: DisplayString
- name: cpmCPUTotal5secRev
oid: 1.3.6.1.4.1.9.9.109.1.1.1.1.6
type: gauge
indexes:
- labelname: cpmCPUTotalIndex
type: gauge
version: 2
auth:
community: public
blackbox-exporter
- config.yml
example.ymlを流用したので省略。
ここまでで収集の設定は完了します🍵
ここからpromQL - Prometheus Query Languageの時間です🆒
取得データの参照
今回、promQLは初めて触りました。
RDBなどのデータ抽出が得意なのでSQLに脳内補完しながら、
クエリを考えると自分は抽出イメージが付きました。
第1段階(Prometheus上)
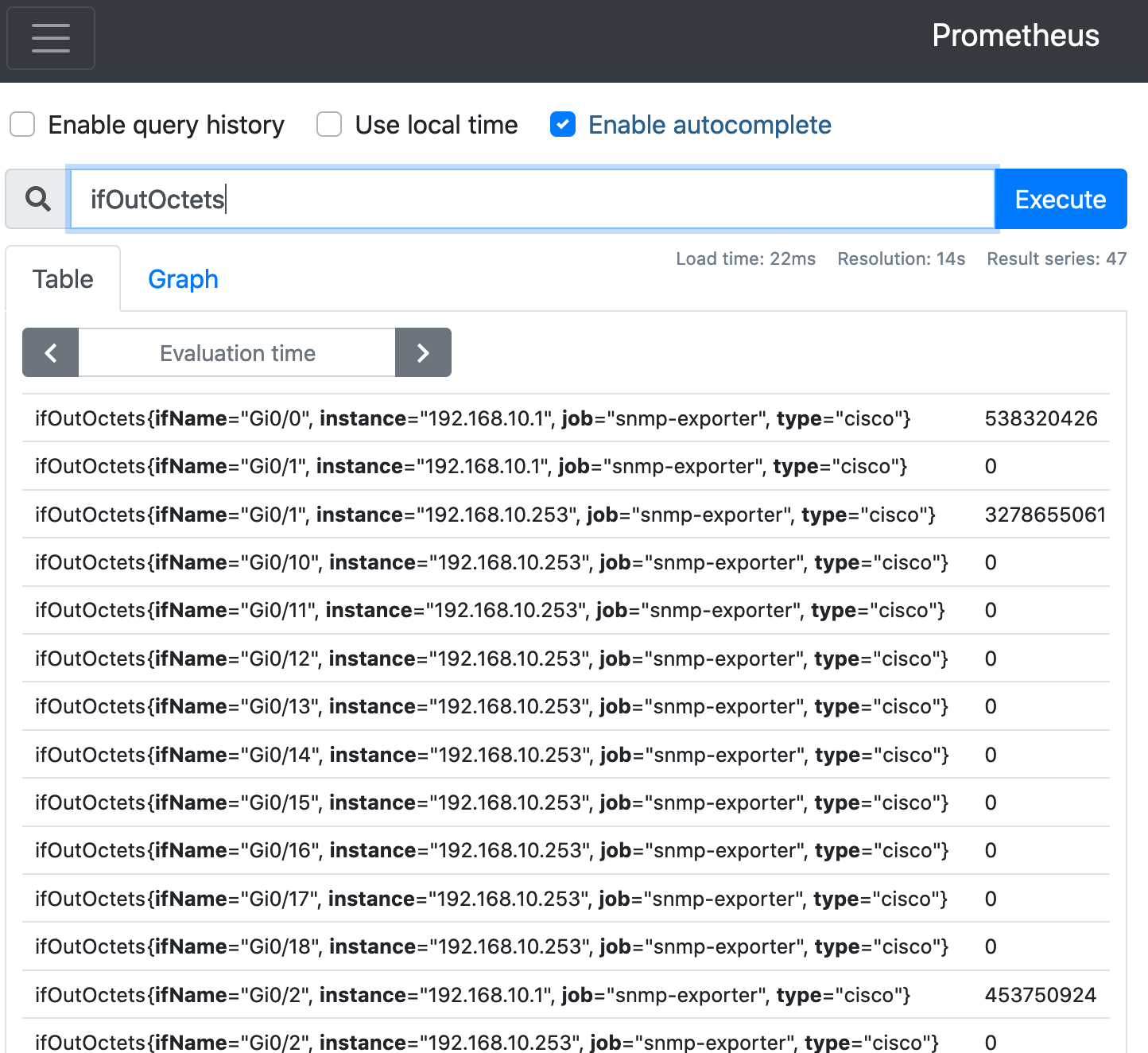
まずはSNMPで取得したデータを見てみる👀
ifOutOctets ( = SELECT * FROM ifOutOctets ; )
第2段階(Prometheus上)
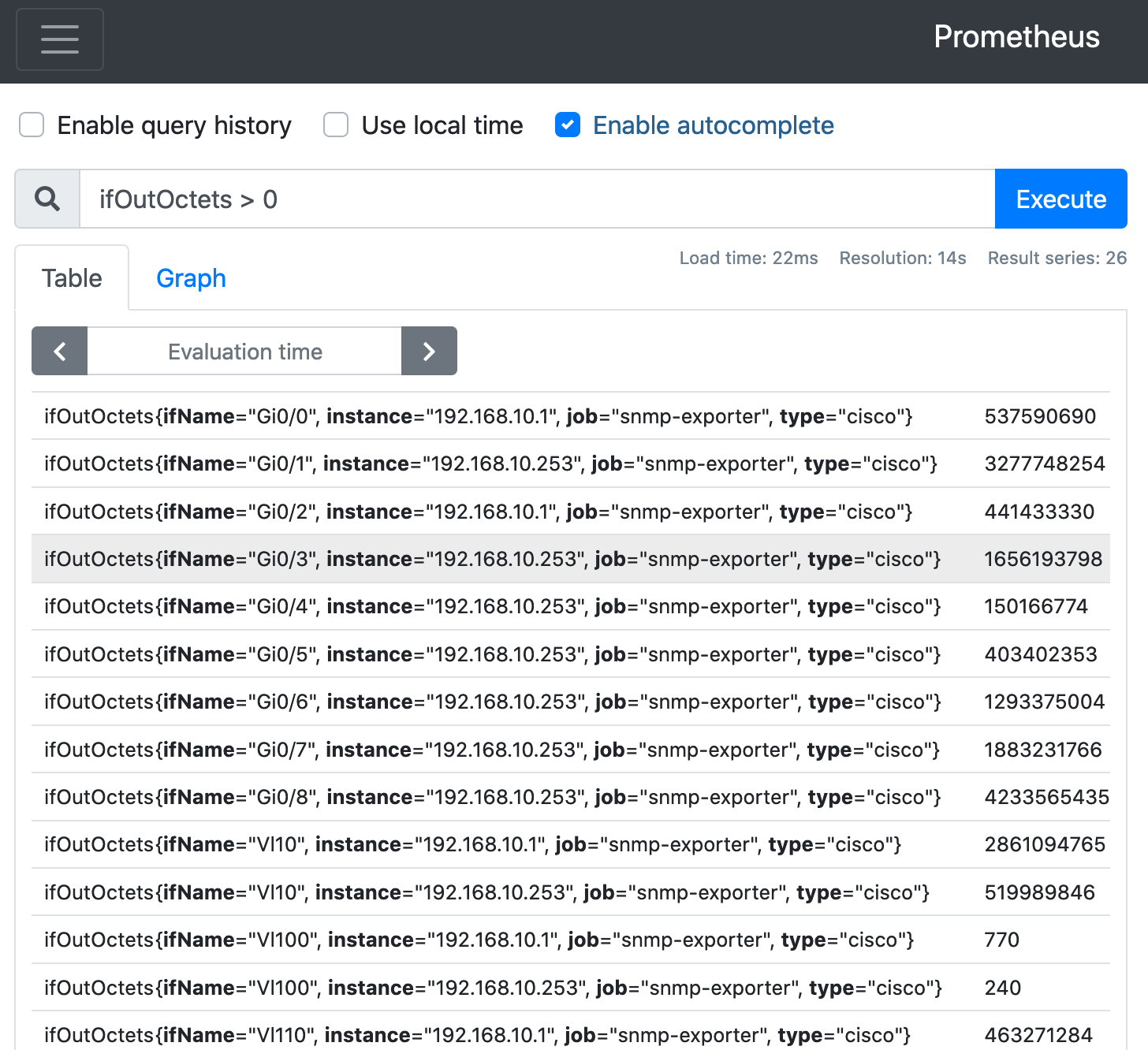
使っていないインターフェース(値が0)が邪魔だな😣
ifOutOctets > 0 ( = SELECT * FROM ifOutOctets WHERE value > 0 ; )
第3段階(Prometheus上)
インターフェースと機器に集約したいな😋
sum by ( ifName, instance ) ( ifOutOctets > 0 ) ( = SELECT ifName, instance FROM ifOutOctets WHERE value > 0 GROUP BY ifName, instance ; )
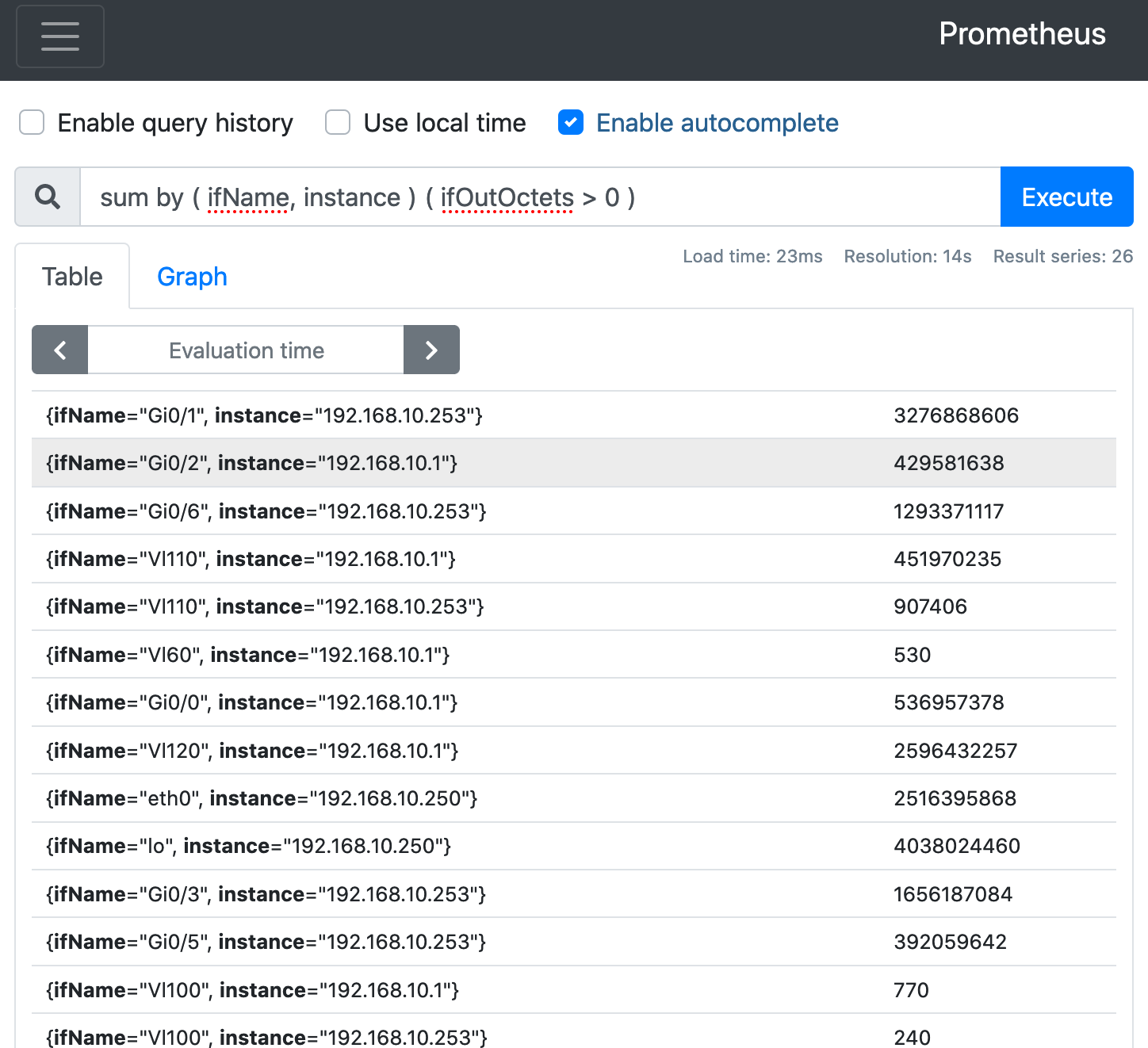
第4段階(Prometheus上)
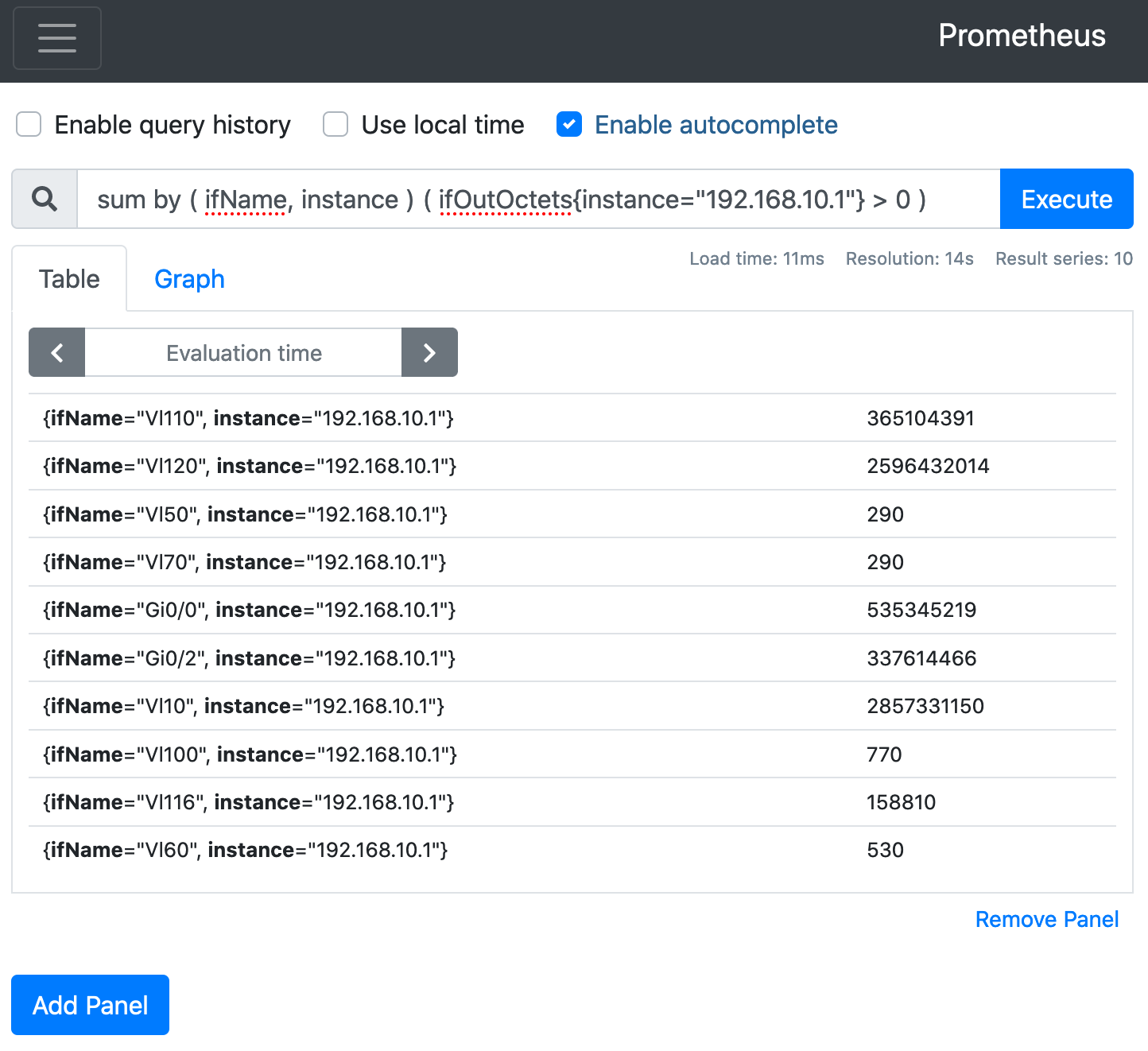
機器別に条件を付けられないかな😆
sum by ( ifName, instance ) ( ifOutOctets{instance="192.168.10.1"} > 0 ) ( = SELECT ifName, instance FROM ifOutOctets WHERE value > 0 AND instance = '192.168.10.1' GROUP BY ifName, instance ; )
第5段階(Grafana上)
一旦、自分の中でいい感じにまとまったので、Grafanaでパネル作成📈
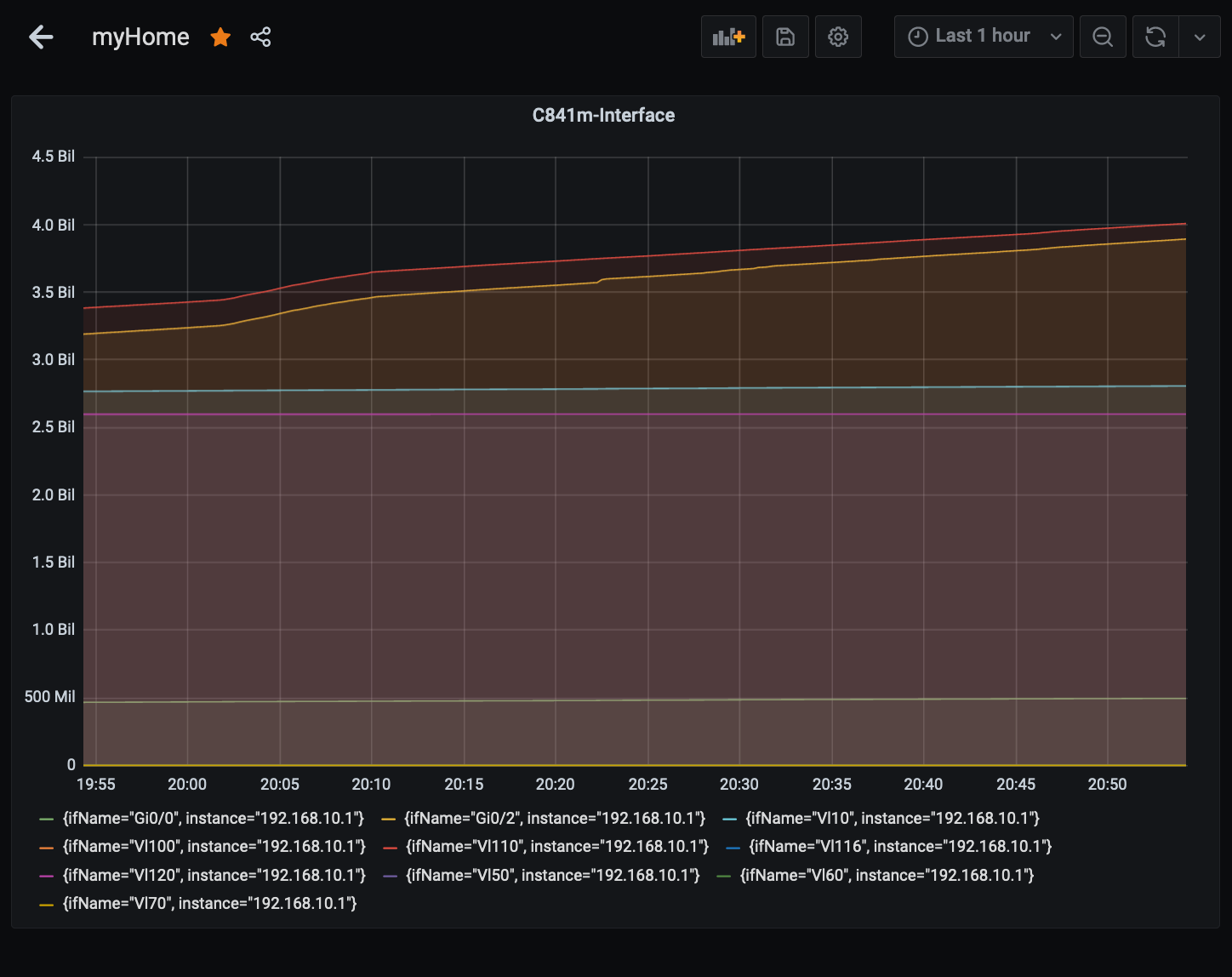
このような形で、promQLを組み立てていきました。
他にも、とりあえずping応答があるものを表示するときのクエリなどは以下の通り記載しました。
count ( probe_success{ job="blackbox_icmp" } )
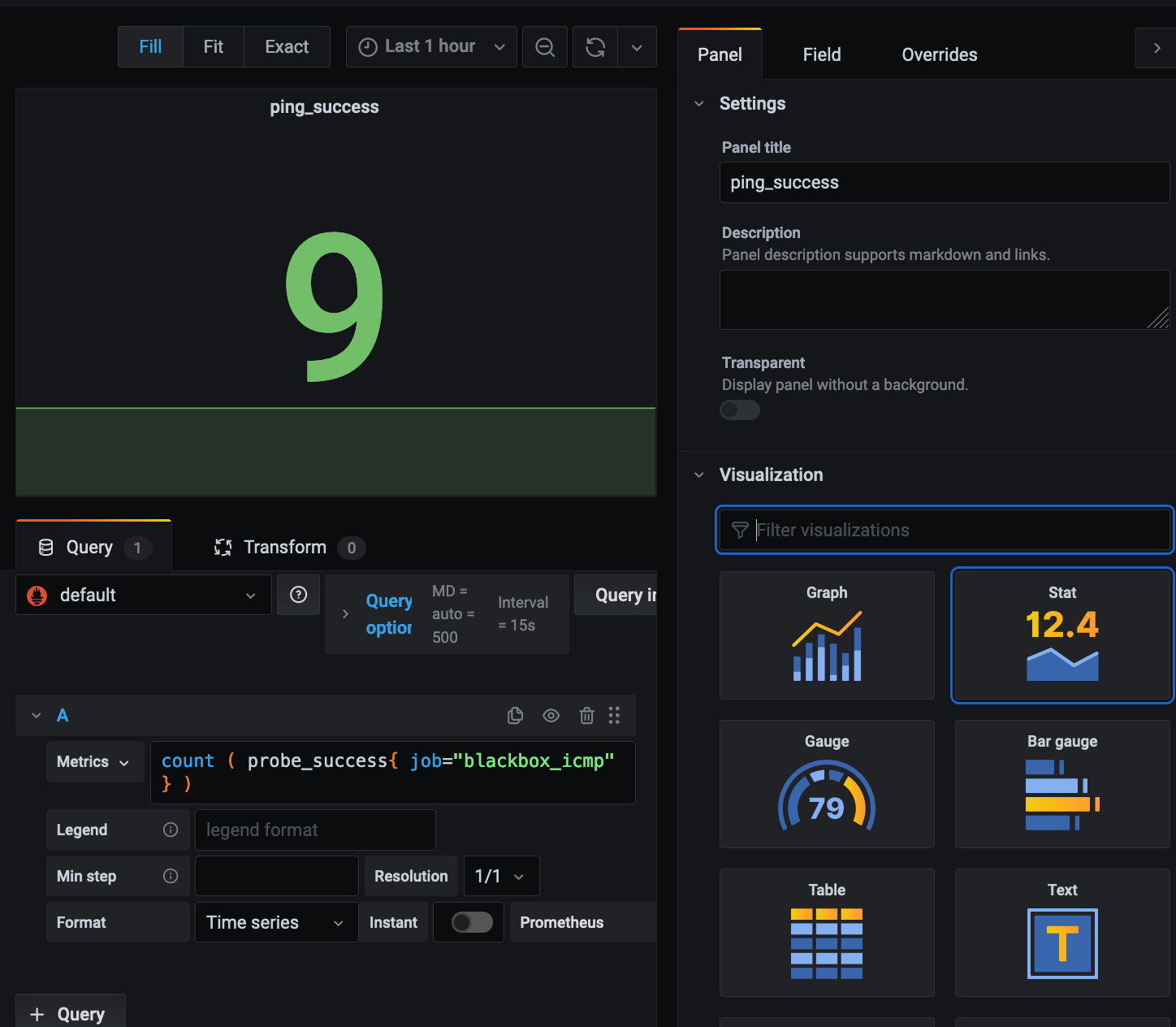
監視の通知
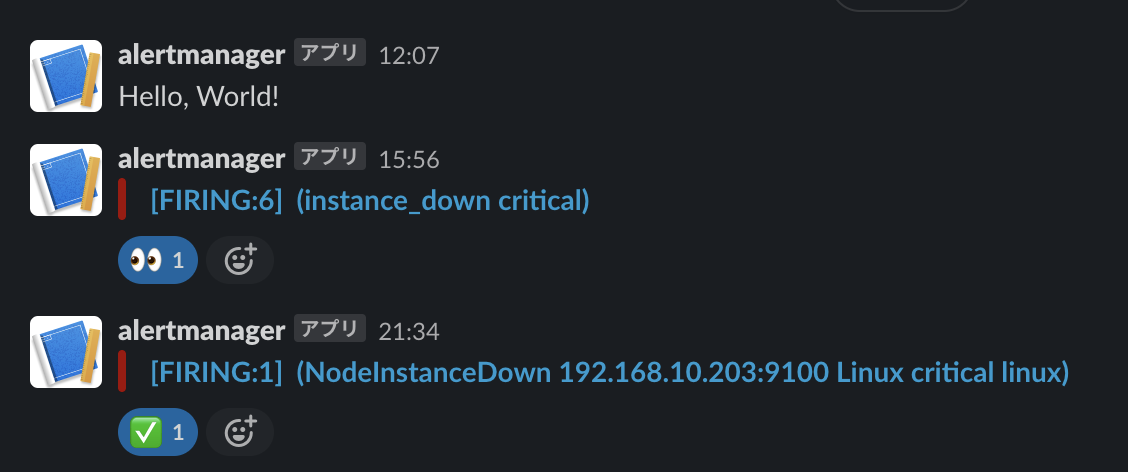
自宅内なので、死活監視程度でまずはいいかなと思って、ダウンさせて問題なく通知も確認できました。
まとめ
今回週末の午後を使って、一気に取り掛かりました。
Prometheusと周辺のイメージ間との通信や、configuration周りで記載ミスがあったりで、
起動までに手こずることもありましたが、無事に自宅内監視基盤を変えることができました。
今回は、自宅内のオンプレミスだったこともありネットワークも特定されていて、
機器も分かっていることもあり設定は容易でしたが、CNCFの卒業プロジェクトに2018年になってから、
触る機会を作っていなかったものの、今回に機会を作ることでまずは体験してみることができてよかったです。
公式ドキュメントから基本的にスクレイピングの設定方法もあるので、
まずは自宅内で運用の経験を積んでから、クラウドネイティブな監視方法を学んでいこうと思います。
ようやくクラウドジャーニーとして一歩を踏めたかなと思いました。
_meta_ec2_tag<tagkey>: each tag value of the instance
__meta_ec2_vpc_id: the ID of the VPC in which the instance is running, if available
_meta_gce_label<labelname>: each GCE label of the instance
__meta_gce_project: the GCP project in which the instance is running
__meta_gce_subnetwork: the subnetwork URL of the instance
__meta_gce_tags: comma separated list of instance tags